Full Extract Staging table
The full extract pattern extracts all the data from the source (table, view, query, file, SaaS) and loads the data into an Azure Data Lake. It also loads the data into an Azure Data Warehouse.
Dimodelo manages the Azure data lake. It stores the files in a prescribed folder structure shown below:
|- Staging Table Name
|- Transformation Name
|- Archive
|- Date
|- Batch Id
|- Landing
|- Latest
- Staging table name folder. Staging table Each Staging table has its own folder. To use the data for data science purposes, just address the Staging table folder to get all the data for the staging table.
- Transforn Name folder. Each transform/extract defined for the staging table also has its own folder. There may be multiple extracts for each staging table.
- Landing/Archive folder. The folders are then split between landing and archive. The landing folder contains the “in-progress” data that has been landed as part of the currently executing extract. Once the extract and load into Azure Data Warehouse are complete, the data is moved from the landing folder to the archive folder.
- Date folder. Below the landing folder is a date folder, representing the batch effective date of the batch loading the data.
- Batch Id folder. The last folder is a Batch Id folder. An extract can be run a number of times during the day. Each run gets a unique Batch Id.
Dimodelo manages data retention in the Azure data lake. You can configure a retention period for each transform/extract to keep the data forever, or for a number of days. When a ‘retention period’ is specified, Dimodelo retains that number of days of date folders in the archive directory and deletes any date folders past the retention date.
After data is loaded into the Azure Data Lake, Dimodelo will run a Create Table As (CTAS) statement in Azure Data Warehouse to load the data into a temporary table (implemented as a real table in a “temp” schema). The CTAS utilizes Polybase. Dimodelo creates the necessary External File formats and External Data Sources to enable the CTAS to extract data from the files in parallel.
After the temp table is created Dimodelo Data Warehouse Studio runs another query, comparing the data in the persistent staging table with the data in the temporary staging table. In this way, it implements change data capture internally. It writes the delta changeset (the set of data that has been inserted, updated or deleted) to another temp table, then swaps the delta temp table for the original temp table. The result is a temp staging table that contains the set of changed data that needs to be applied to the persistent staging table to bring it up to date with the source. Note, the ‘incremental’ and ‘change tracking’ extract patterns skips this step, as it initially only extracts the delta change-set to begin with.
Create a new “Service” Staging table
- Expand the Staging folder, right-click Persistent Staging and click Add New.
- Select “Service” in the Source System field. The Source System is used to define the name of the Staging table in the Staging database. The table name in the Staging database will be Schema.Source SystemAbbreviation_Staging Table Name.
- In the Staging Table Name field type “Service“. The name is used to define the name of the table in the Staging database. The table name in the Staging database will be Schema.Source System Abbreviation_Staging Table Name.
- Enter the “This is a Service persistent Staging table” Description in the Description field. This is optional. The Description is used as an overview for the table in the generated Documentation.
Staging Columns
The quickest way to define the columns of the Staging table is to import the column definitions from a Source table. If there isn’t a matching Source table, then you can manually define the columns. To import a Source table do the following:
- Click on the Staging Columns tab.
- Click the Import Schema button.
- Select “Service” in the Connection dropdown. The Import Table field is populated with tables and views from the source.
- Select the “dbo.Service” in the Import Table field. You can also start typing dbo.Ser… and the match values will display for selection.
your result should look like this:
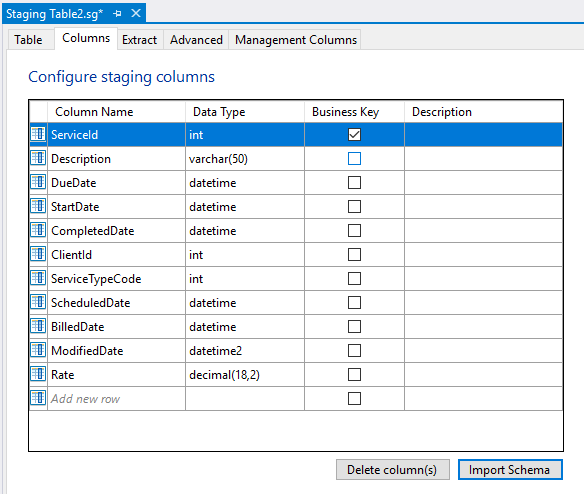
- Add a new staging column. Click in the cell that says “Add new row” and type “Category“.
- Click in the Data Type column and type “varchar(50)“.
- Click Ok. The columns and data types of the source table are imported into the Staging table design.
Further Information
- Modify a Column Name. Tip… Only modify the column names after you have defined an Extract. That way Dimodelo Data Warehouse Studio will automatically match the columns in the Source table with columns in the Staging table based on the name when you edit the mapping in the Extract. After that, you can come back and change the name, Dimodelo Data Warehouse Studio recognises the name change. The Column Name becomes the name of the column in the Staging Database.
- Modify a Column Data Type. You can change the data type of a staging table column. Note, This may mean you need to modify the Extract to convert the data type of the Source column in column mapping using an Expression.
- Add a Description. This is optional. The Description is used in the generated Documentation.
- Delete a Column(s). Select the column(s) and click the Delete column(s) button.
- Add a Column. You will need to add a mapping in the Extract if you add a column.
Dimodelo Data Warehouse Studio will Sync the column changes when the Data Warehouse is deployed.
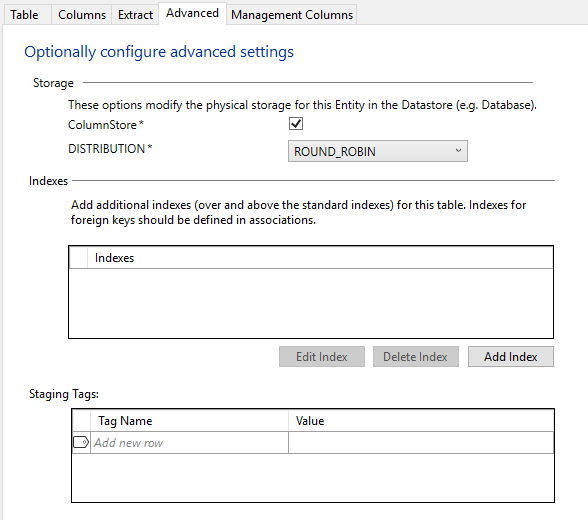
Advanced Tab
On the Advanced tab, you will be presented with additional properties for the staging table. These properties are based on the target technology for the data warehouse. In this case, the target technology is Azure Data Warehouse, so you are presented with a DISTRIBUTION option with a default.
- ColumnStore.Tick the ColumnStore tick box. The deployed persistent staging table will be created with a clustered column store index. A clustered column store index can’t co-exist with other clustered indexes. In this case, we are just deleting all other indexes.
- Select the “Business Key” index in the Indexes table and click Delete Index. Click Delete in confirmation warning dialog box that appears.
- Select the “Latest” index in the Indexes table and click Delete Index. Click Delete in confirmation warning dialog box that appears.
Your result should look like this:
Add an Extract to the Staging table
- To define an Extract select the Add button on the Extract tab. The Extract dialog appears.
Overview Tab
- Extract Name. Keep the default Extract Name. The Extract Name is important as it is used to uniquely identify the Extract and is used by the standard generation templates to name the generated code artefact. E.g. A stored procedure might be called Extract_Extract_Name. The name defaults to source system abbreviation_Staging table name. Make sure the name matches a task in the Workflow (it will by default). See more about Workflows in the Batch Management Facility document.
- Extract Pattern. Select the “Full Extract” in the Extract Pattern field. The selected pattern is used to determine the type of code that will be generated for this Extract.
- Extract Overview. Optional. Enter a description of the extract for documentation purposes.
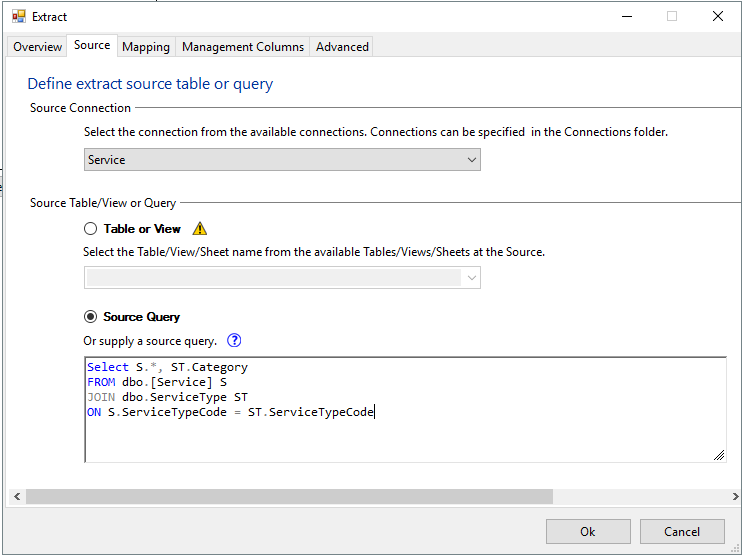
Source Tab
The Source tab defines the source table or query of the Extract.
- Connection. Select the “Service” connection in the Connection dropdown.
- Source Query. Select the Source Query option. This enables the source query text box.
- Copy the following query into the Source Query text box.
Select S.*, ST.Category FROM dbo.[Service] S JOIN dbo.ServiceType ST ON S.ServiceTypeCode = ST.ServiceTypeCode
Your result should look like this:
Mapping Tab
The Mapping tab defines the column mappings between the source columns and the staging table columns. The mappings may also be expressions. The mapping happens automatically based on a name match between the source and staging table columns.
- The mapping table should be pre-populated with column mapping between the source table/query and staging table columns. There is nothing to do.
- Click on the “Rate” row and click Edit Mapping button.
- Select the Expression option.
- Type “Rate * 1.1” into the Expression text box.
Your result should look like this:
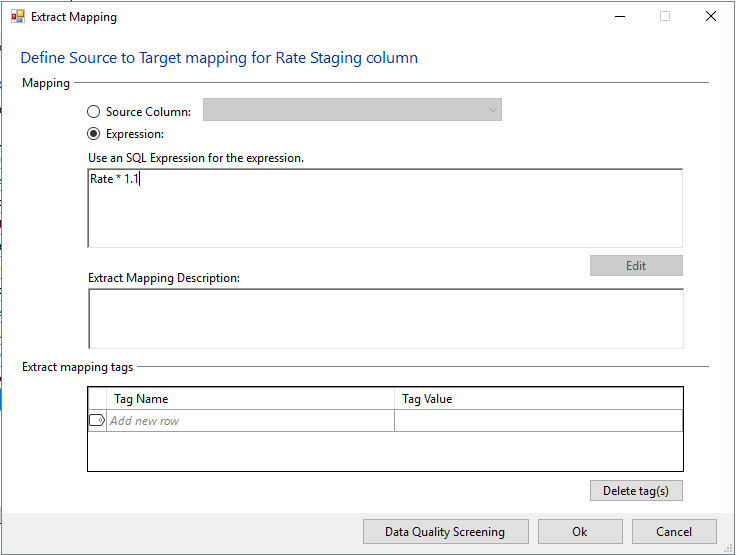
- Click Ok.
Your result should look like this:
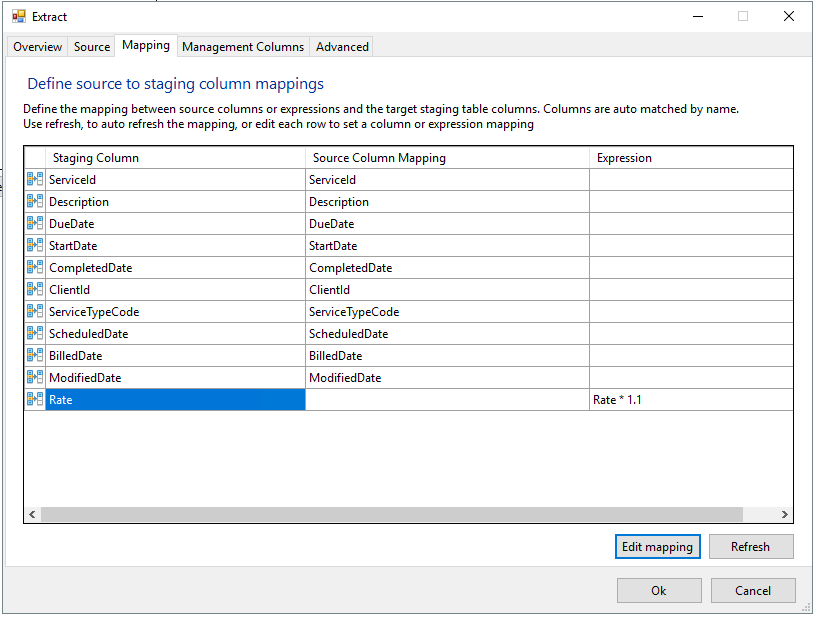
- Click the Ok button at the bottom of the dialog to save the Extract.
- Click the Save (disk icon) on the Visual Studio toolbar to save the Staging table.
Further Information
- Staging Column. The Staging Column is the name of a Staging table column. The Staging Column is populated from the list of columns defined for the Staging table.
- Source Column Mapping. The Source Column Mapping is the name of the Source column that maps to the Staging table column. This field is auto-matched based on the name after a source is selected in the Source tab.
- Double click the column or select and click Edit mapping and the Extract Mapping dialog appears. In the dialog you can change the setting for the column, define an expression mapping, and add a description to the mapping for documentation purposes.
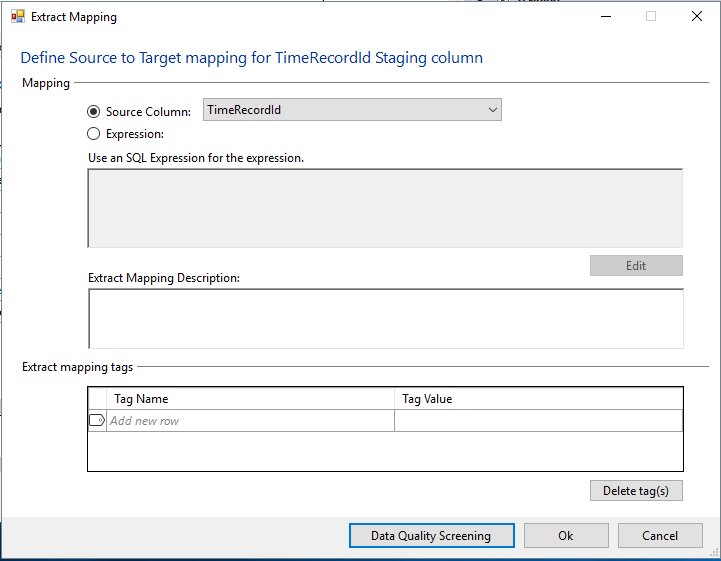
-
- Source Column Mapping. Select a different Source Column mapping for the Staging column from the drop-down.
- Write an Expression for the mapping. Note the Expression can only reference source columns (not staging columns). The Expression is T-SQL and must be a valid SQL expression when executed against the Source database. It should be written as if the expression will be part of a Select clause. E.g. SELECT expression FROM Source Table.
- Extract Mapping Description. A description of the mapping for documentation purposes. Non Mandatory.
- Extract Mapping Tags. Define custom metadata for the mapping particular to the chosen Extract pattern.
- Data Quality Screening. Future functionality.
Advanced Tab
On the advanced tab, you will find additional properties for the Extract. The properties are different depending on the target technology of the Staging data store defined in the configuration. In this case, the target technology is Azure Data Warehouse and Azure Data Lake.
The properties include:
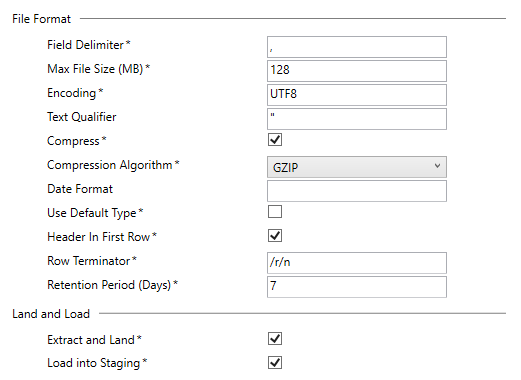
File Format
These properties describe the format of the files that are loaded into the Azure Data lake. The defaults are based on best practice, but you can change these per entity. The only format supported at the time of writing is CSV files. Other formats may be supported in the future. These setting are also used when defining the External Data Source in Azure Data Warehouse for Polybase extracts.
- Field Delimiter. The field delimiter in the CSV file. The delimiter between field values. e.g. a comma.
- Max File Size (MB). The max size of the file that will be loaded into the Data Lake. For example, if the max size was 10MB, and 100MBs was extracted, then 10 files would be created, zipped and uploaded.
- Encoding. The encoding of the file. Valid values are UTF8 and UTF16. UTF8 is approx half the size of UTF16 in many languages.
- Text Qualifier. The character that qualifies text in text fields in the CSV files. e.g. a double quote.
- Compress. Choose to compress the file before being uploaded to the Data Lake.
- Compression Algorithm. The algorithm used to compress the file, only GZIP is supported.
- Date Format. A custom date format that Polybase uses to load data. Only leaving this blank is supported by the default generation templates. The current Dimodelo Data Warehouse Studio pattern treats dates as text until it reaches the Azure Data Warehouse where it is converted into the correct date type.
- Use Default Type. Use the polybase default date types. Leave as unticked.
- Header In First Row. Add column headers as the first row of the file.
- Row Terminator. The value to use as the row terminator of the file.
- Retention Period. The number of days to keep the extracted data in the Data Lake. 0 = keep forever. E.g. 7 = keep 7 days of Extracts.
Land and Load
You can choose to just ‘Extract and Load’ the data to the Data Lake, just ‘Load into Staging’ (i.e. Load the data into Azure Data Warehouse Staging from the Data Lake from a pre-loaded Azure Data Lake file), or both.
- Extract and Load. Tick to ‘Extract and Load’ the data to the Data Lake.
- Load into Staging. Tick to load the data into Azure Data Warehouse Staging from the Data Lake from a pre-loaded Azure Data Lake file.