
Understanding Extract Transform and Load Design
ETL stands for Extract, Transform and Load. It refers to the process of extracting data from the Source systems, transforming it into the star schema format and loading it into the relational Data Warehouse. Development of an ETL process is the major cost in delivering a Business Intelligence Solution. Up to 80% of your cost will be in developing the ETL.
ETL is complex. You could write an entire book about ETL, and several people have including Kimball himself, including the 34 Subsystems of ETL. This section will just provide an overview of ETL processes. The “Develop a Data Warehouse with Dimodelo Data Warehouse Studio” course is an in-depth description of using Dimodelo Data Warehouse Studio to build a Data Warehouse and its ETL.
On the surface ETL looks simple. It’s merely extracting data from one data source and inserting it into another. But once you delve in to it, it becomes more difficult with lots of use cases that must be managed. For example, how do you handle the following:
- Inserted, Update, Deleted at Source.
- Late arriving Rows.
- Duplicates.
- Persisting data and keeping an accurate history.
- Heterogeneous Source systems and Connectivity.
- Identifying changed data at source.
- Identifying changed data at target.
- Deleted Rows being reinstated.
- Type 1 and 2 SCD. Type 1 Only, Type 2 Only and Type 1 and 2 mixed Dimensions.
- Schema changes of Source and Target entities.
- Data Quality.
- Full,Partial or Incremental sources and joins across each source.
- Restarting failed processes.
- Deployment to Multiple Environments.
- Scheduling and Orchestrating Batches.
And that’s just the start. It can take several months at least to derive effective ETL patterns.
In addition, ETL techniques are constantly changing. With the advent of the cloud, with a limited “pipe” between on-premise data sources and a cloud based data warehouse, and with different data load techniques targeting new technologies (Massive Parallel Processing Databases, Data Lakes, Big Data), the nature of ETL has changed significantly. ETL that worked on on-premise databases, won’t work for the cloud environment.
Dimodelo Data Warehouse Studio solves many of these issues for you. It comes with Data Architecture and ETL patterns built in that address the challenges listed above It will even generate all the code for you. Dimodelo Data Warehouse Studio is a Meta Data Driven Data Warehouse tool. It captures meta data about you design rather than code. That meta data can then be used to generate code for a variety of evolving platforms and technologies.
ETL vs ELT
Extract Transform/load (ETL) is an integration approach that pulls information from remote sources, transforms it into defined formats and styles, then loads it into databases, data sources, or data warehouses.
Extract/load/transform (ELT) similarly extracts data from one or multiple remote sources, but then loads it into the target data warehouse without any other formatting. The transformation of data, in an ELT process, happens within the target database. ELT asks less of remote sources, requiring only their raw and unprepared data.
ELT is gaining popularity because of the exponential growth of high scale processing power with database platforms themselves, like MPP databases, Big Data Clusters etc. ELT also has the advantage of keeping large amounts of historical unprocessed data on hand ready for the day it may be needed for new analysis.
ETL Process
There are as many ways to design ETL as their are designers. The diagram below describes the ETL and Data stores utilized by Dimodelo Data Warehouse Studio when generating a Data Warehouse solution. This borrows heavily from the Kimball methodology, but also incorporates our learning over many data warehouse implementations, the advent of the persistent staging concept, and the advent of Cloud based Data Warehouse solutions.
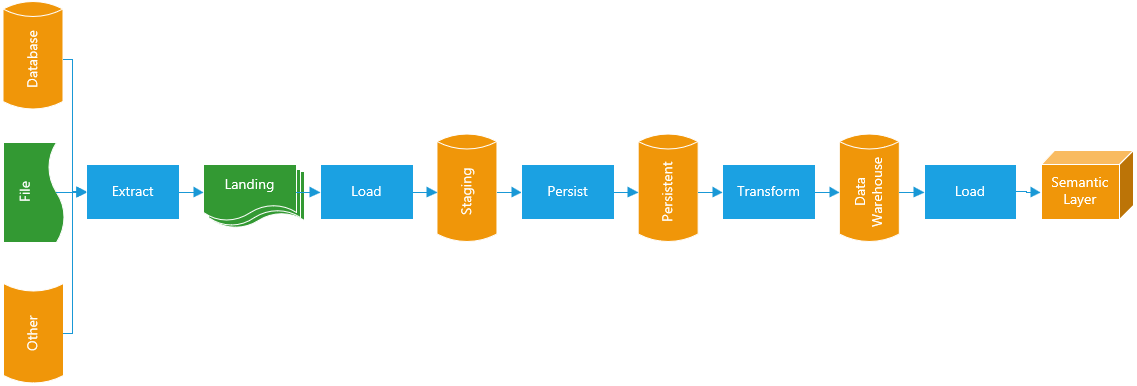
Extract
The extract process pulls data from a source system, usually on a nightly basis. Source systems can include Databases, Text Files, Excel spread sheets, or any other kind of source data. The data is written to a Landing data store, typically a local or cloud based file system ready for loading into the Staging/Persistent Layer. Conceptually, because of it’s file based nature, the Landing data store could be the raw data layer of a Data Lake. For the purposes of the Data Warehouse, the Landing Data Store is transient, meaning it doesn’t persist the data between ETL batch runs. Several patterns for Extract can be employed:
- Full Extract. All the data in the source entity is extracted. In this case change data detection occurs during Load.
- Incremental Extract. Only the changed data is extracted from the source. In this case, the Load does not need to do change detection. This method is much faster. However, the source entity must support it. For the pattern to work you need to identify a column or multiple columns that the source system uses to track change. They would usually be a modified date or sequential identifier. The down side of this pattern is that it doesn’t detect hard row deletes form the source. That makes it necessary to run a period Full Extract as well.
- Change Tracking. The change tracking pattern, uses the Change tracking mechanism of the source database (e.g. Change Tracking in Microsoft SQL Server) to identify change in the source entity and to extract only changed data. The Change Tracking pattern has an advantage over the incremental pattern, in that, it does recognize hard deletes, and is therefore a superior pattern if available.
- File Pattern. Extracting data from files is different. There may be multiple files that match a file name pattern. The files also need to be archived after data has been extracted from them. A specialized pattern is required.
- Date Range Pattern. The date range pattern is used to extract a subset of the source data based on a date range. The end of the date range is the current batch execution date. The start of the date range is a number of days prior to the current batch effective date. Each time the ETL runs, the current batch effective date, for that batch execution, is set to midnight of the prior day. The date range ‘window’ moves forward a day as the current batch effective date changes. To use this pattern, its important that dependent entities further up the chain are also working with the same date range.
Load
Load is the process of loading data from the landing data store into the staging data store. The staging data store is typically a database co-located with the Data Warehouse database. It could potentially be the same Database. The staging data store is transient, meaning it doesn’t persist the data between ETL batch runs. In the case of a Persistent target entity, the staging entity is very short lived, only existing until it has been persisted in Persistent data store.
It is necessary to stage data for a number of reasons:
- Staging places less load on source systems. Extract procedures are keep as simple as possible. The next steps, load, persist, transformation etc may require complex queries, that you don’t want to run on the source, mission critical, system.
- If you are combining data from more than 1 source system, then you need to stage data from all those systems before you can combine the data in the transformation step.
- Staging gives the Data Warehouse the opportunity to implement its own change data capture and data quality screening across source systems.
- Staging allows more rapid failure recovery, because the data does not need to be Extracted a second time on recovery.
Persist
A Persistent Data Store, store all change history of the source entities. Technically it is a Bi-temporal database. Every row in a Persistent Entity has a Start and End Effective date. Each row is also associated with the an inserted and last updated batch Ids, that are related to a date.
- Provides the ability to re-load the data warehouse layer with full history if required (due to a change in logic, model or mistakes).
- Improves ETL efficiency. It becomes possible to do incremental (delta) loads at all levels.
- Without Persistent staging, it was difficult to do complex transform logic over the data from incremental extracts into staging tables. These staging tables would, on any given day, only have a small subset of rows from the source table/query. It was impossible to join these tables to other tables to get some other representation of the data that needed more than just the subset that was available.
- Provides trace-ability and audit-ability of data.
An example of the power of persistent staging is the analysis of the rate of change for scheduled Visits. Scheduling visits across a large complex home care service is complex. This can lead to a lot of schedule and route changes.The persistent layer can capture all these changes and can be used to analyse the rate of schedule “churn”. Schedule churn can be very disruptive and ultimately costly to the organisation. In addition, this schedule churn can lead to questions about “Why did my report change”. The persistent staging layer provides evidence that the source data is changing, and not the report logic, or a problem with the report.
The Persistent ETL takes data from the temporary load data store, generates a delta change set if the data has come from a full extract, then applies that change set to the Persistent entity, inserting new versions of rows and end dating existing rows where necessary.
Transformation
Transformation is the process of transforming the data in either the staging or persistent data stores into the star schema format, and loading it into the Data Warehouse. This is where data staged from multiple source systems is combined into a cohesive set of Facts and Dimensions. There are many techniques required to identify change and implement high performance data loading into the data warehouse. Because it is easy to identify the changed data set from persistent entities, Transform ETL that uses the persistent data store as its source is incremental. Incremental ETL is a design technique for improving ETL throughput.
Semantic Layer
The Semantic layer is the layer/data store that BI tools connect too. The semantic Layer in the Microsoft world is generally an OLAP Cube, a Tabular model, or a PowerBI data set. There are “virtual” semantic layers that pass through queries to the data warehouse. Unless the Data Warehouse is utilizing advanced technology like column stores and MPP, then its likely the queries won’t execute as quickly as if they aren’t cached by the semantic layer. The semantic layer is also transient. It is reloaded from the Data Warehouse on regular intervals. The Semantic layer is a high performance aggregated query engine. The emphasis is on aggregated. The mentioned technologies don’t perform as well on non aggregated queries. Non aggregated queries (like lists of transactions) will perform better when run directly against the data warehouse.
Throughput
ETL throughput is important especially with large quantities of data. Throughput is generally addressed in 3 ways:
- By Design. For example, Incremental extracts are much faster than Full extracts.
- Through Parallel processing. By splitting the work of a single process over different compute units (e.g. servers) like an MPP database (Azure Data Warehouse).
- Concurrency. By running multiple processes (i.e. Extract, Load, Persist, Transform) at the same time for different entities. Your Extract is running on-premise using on-premise compute, your load is running on the data lake using poly-base compute, and the Transform is using Azure DW compute.