What is a Semantic Layer? (and why you need one)
What is a Semantic Layer
A semantic layer exists to present data to users as a set of related and commonly understood business entities, terms and metrics.
A semantic layer is typically the “top” layer of a data warehouse/lakehouse. It is accessible to end users and report developers, who use it as the source for reports, dashboards, and ad hoc analysis.
A semantic layer is important because it fosters a shared understanding of information across the business. It supports the autonomous development of consistent reports, analysis and dashboards by end users.
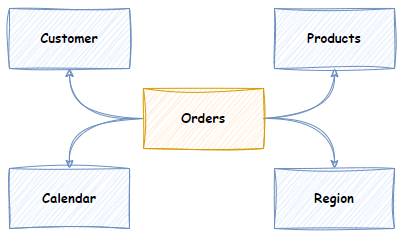
A semantic layer is:
- First, a business glossary. The basis of a semantic layer is a glossary of related commonly understood business entities, terms and metrics, e.g., The concepts of a Customer, Product, Sale and the relationship between Sales and Products, and Sales and Customers.
- Represented as a “business view” of data. Physically, the “business glossary” exists as a “business view” of enterprise data. The “business view” is implemented in the semantic layer. The semantic layer is typically the highest/final layer of a data warehouse or data lakehouse implementation. The raw enterprise data undergoes a series of transformations to arrive at the semantic layer’s “business view” format. The most common “business view” format is a dimensional model.
- Accessible to BI developers and end users. The semantic layer is accessible to end users, data analysts and BI developers. It’s the source of data for reports, ad-hoc analysis and dashboards.
- Supports Autonomy. A semantic layer supports autonomous access and navigation of the data. It supports self-service BI and ad-hoc (drag-drop) analysis.
- Fosters a shared understanding. A semantic layer fosters a common understanding of enterprise data amongst all business users.
Why do you need a Semantic Layer?
In large and small businesses today, there are challenges in producing consistent reports.
Without a semantic layer, users, data analysts and BI developers inevitably use data from a variety of sources to develop reports, etc. These reports will often contain conflicting definitions and calculations. These contradictory reports generate a lot of confusion. Business users waste time arguing about these differences with little possibility of resolution. Ultimately, without a semantic layer, the quality and trust in the data on which decisions are made is eroded.
In contrast, semantic layers provide a shared understanding of business terminology and a “single source of truth” for reporting etc. Users, data analysts and BI developers use this “single source of truth” as the source of all reports, etc. This promotes a common business language and understanding and fosters trust, quality, and user collaboration. In addition, it encourages reuse and reduces duplication of effort and waste.
Physically, semantic software in a Data Warehouse or Data Lakehouse architecture provides the following benefits:
- High-performance aggregated queries. Sub-second response time to aggregated queries over billions of rows.
- Augments and Enhanced Information. The ability to enhance and simplify the information in the underlying Data Warehouse or Data Lakehouse, including:
- “Cleaning up the model” to Hide tables, columns, and relationships irrelevant to the business.
- Adding Hierarchies. Hierarchies enable hierarchical reports, drill-downs and more straightforward navigation.
- Adding reusable context-aware calculated metrics.
- Renaming tables and columns if necessary (although your data warehouse, if modelled correctly, should already use the correct naming standard).
- Unified Data. Semantic models can combine data from multiple sources. Indeed, an end user could enhance the data warehouse with their own data source in the semantic layer.
- Support for BI tools. Many BI tools natively support connecting to and querying semantic layer software.
- Context-Aware Security. Restrict data access based on tables, rows, columns and formulas.
The different Types of Semantic Layers
The semantic layer tends to fall into four categories:
1. Data Store or fat semantic layer
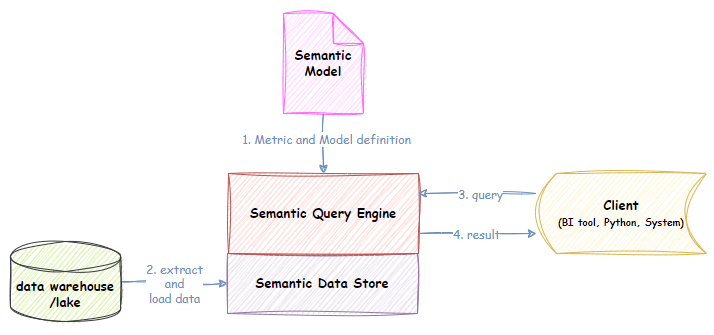
The Datastore flavour contains a complete additional copy of the Data. The data is stored in a proprietary, highly compressed and optimised format (usually column store). This flavour comes with an internally optimised vector-based query engine. The Datastore flavour tends to perform better than the Virtual flavour because these data stores are structured to support high-performance aggregated queries. The emphasis is on aggregated. The data store is usually transient and re-loaded periodically from the Data Warehouse. Example technologies include Microsoft Azure Analysis Services, PowerBI data sets, Kyligence, GoodData, Apache Druid and Apache Pinot.
- Advantages:
- High performance for aggregated queries
- Easier to define security.
- It contains functional query languages that make it possible to define complex metrics.
- Disadvantages:
- Increased complexity and cost to load an additional datastore.
2. Virtual or thin semantic layer
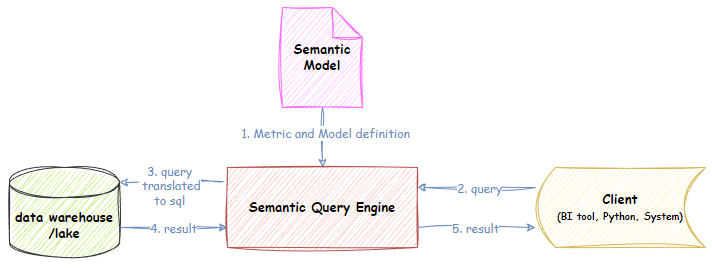
The virtual semantic layer doesn’t store a separate copy of the data (although it might cache data for performance). Instead, the virtual semantic layer contains the logic that defines the semantic model. When a query is executed, the virtual semantic layer acts as a proxy and generates and runs an SQL query against the underlying data source(s). Examples of technologies include Cube, Malloy, LookML, Metriql, AtScale, MetricFlow, Metlo, and Denodo.
- Advantages:
- Avoids data movement to an additional data store.Lower complexity.Lower cost due to less data storage.
- Disadvantages:
- Tend to be slower than data store-based semantic layers optimised for aggregated queries. Caching and pre-computation can elevate some of this disparity, but not all; frankly, it moves this solution toward the hybrid option anyway.
3. Hybrid semantic layer
Hybrid flavours support both datastore and virtual modes. Developers can generally define which tables within a semantic model are stored vs virtual. This can help with the trade-offs of performance vs complexity/capacity. In some cases, the data may be so large it is beyond the capacity of the semantic platform to store it. It could be argued that virtual caching is one way to achieve a hybrid model. A better example is Power BI datasets that allow a single semantic model to have a mix of stored vs virtual (direct query) tables.
4. Meta Semantic layer
This is a relatively new development in semantic modelling. Effectively, companies like dbt allow developers to define metrics in a platform-agnostic language. The idea is that dbt can generate the code for a given metric for any supported platform. That’s the idea, at least. Think potentially generating a Power BI dataset or another language for a different platform. This provides portability. It’s very early days, and so far, dbt’s implementation is more focused on supporting its own dbt cloud semantic server. However, the original open-source and open-platform idea persists. Time will tell. dbt Semantic Layer | dbt Developer Hub (getdbt.com)
How are semantic layers implemented?
From a physical point of view, a semantic layer is implemented using specialized software. There are several flavours, which we will expand on in this section.
1. Semantic layer implemented within a BI tool
Modern BI reporting and analysis tools like Power BI, Tableau and Qlik allow data analysts to model a semantic layer directly within a dashboard or report. Some tools will enable you to deploy the semantic model independently from a report and have it act as the semantic layer that many dashboards and reports share.
Ultimately, this approach has issues. An undisciplined proliferation of separate semantic models within dashboards and reports defeats the purpose of a shared semantic layer. What is needed is a disciplined development approach that enforces shared data models.
Power BI has the most comprehensive use case as a semantic layer among the most popular BI tools. While it can support a semantic layer coupled with a report, it can also support a scenario as a stand-alone semantic layer. First, a data set can be published independently from a report and shared by many reports. Power BI premium capacity supports large data sets beyond the typical 10GB up to the capacity size. Power BI has an XMLA endpoint and a REST API that allows external applications to make queries. It enables users to create composite models to supplement data, e.g., a budget Excel spreadsheet combined with actuals from a data warehouse. Power BI supports stored, virtual and hybrid query models. People have even used Power BI as the semantic layer and Tableau as the client via XLMA endpoints. It also has a highly capable functional language, DAX, an internal Vertipaq/tabular data store, and a query engine.
In contrast, Tableau’s strength is its visual aesthetics. It does support some semantic modelling concepts in its data model. It also supports high-performance queries with its Hyper query engine. However, it lacks the concept of publishing a data model as a stand-alone semantic layer. It also lacks the rich analytics language like DAX.
Semantic Layer implemented in a Data Warehouse/Data Lakehouse Architecture
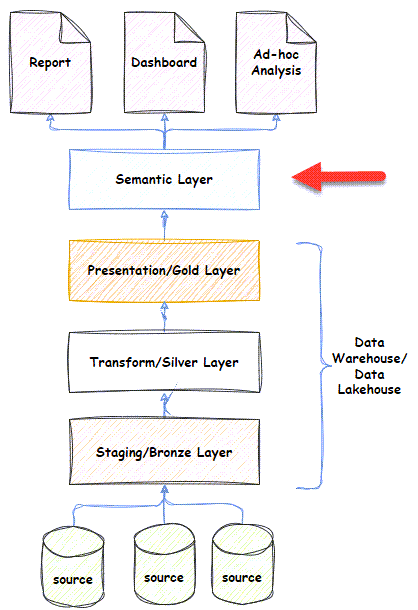
The semantic layer is the final layer of a data warehouse/data lakehouse architecture.
The semantic layer sits between the presentation layer (the gold layer in Data Lakehouse) and the reports/analysis/dashboards. End users can view, navigate, and query the semantic model through a BI tool.
The best practice is to model the presentation/gold layer as a dimensional model. A dimensional model star schema lends itself nicely to semantic layer entities. The core of a dimensional model is business processes, which are modelled as facts with their measures/metrics. The business entities involved in business processes are modelled as dimensions with their descriptive attributes.
Most semantic modelling work and transformation occurs in the presentation/gold layers. The semantic layer should map directly to the Facts and Dimensions in that layer.
So, if the semantic layer looks like the presentation layer, why need a separate semantic layer?
As discussed before, the semantic layer software offers:
- High-performance aggregated queries.
- Augments and Enhanced Information. Enhances and simplifies the information in the underlying Data Warehouse or Data Lakehouse. This includes:
- Hiding tables, columns, and relationships irrelevant to the business, including surrogate keys and management columns.
- Adding Hierarchies. Hierarchies enable hierarchical reports, drill-downs and more straightforward navigation. Adding reusable context-aware calculated metrics.
- Renaming tables and columns if necessary (although your data warehouse, if modelled correctly, should already use the correct naming standard).
- Unified Data. Semantic models can combine data from multiple sources. Indeed, an end user could enhance the data warehouse with their own data source at the semantic layer.
- Supports BI tools. Many BI tools natively support connecting to and querying semantic layer software.
- Context-Aware Security. Restrict data access based on tables, rows, columns and formulas.
- Supports ad hoc analysis. Provides an interface that BI tools use to enable ad-hoc, drag-and-drop, pivotable style data analysis. The data store and query engine behind semantic layer software makes this possible.
Universal Semantic Layer
A universal semantic layer is more about a philosophy or methodology. Personally, I advocate for always building a semantic layer on top of a data warehouse/data lakehouse, and, therefore, don’t endorse the “Universal Semantic Layer” concept.
“Universal Semantic Layer” advocates believe building a data warehouse requires too much effort. They advocate skipping the data warehouse build. Instead, you connect your semantic layer directly to source systems or a raw dataset in a common data store. Then, the semantic layer is used to join and transform that data into the semantic model. When a user accesses the semantic layer, the semantic layer software generates and orchestrates the queries across many sources and joins the disparate result sets to produce the final result.
This approach often lends itself to the “virtual” type of semantic layer software, where the semantic layer is just a thin veneer with a semantic model.
An obvious issue with this approach is performance. The underlying data sources are not specialised in aggregated queries. Joining across source systems often leads to inefficient query plans. The queries can take minutes or hours to return results. To counter this issue, vendors introduce pre-processing and caching, but frankly, this can only achieve so much. Some have even taken to embedding an analytics database behind the virtual semantic model, shifting source data to this analytics database. This sounds a lot like a data warehouse… just worse.
Rather than saving the developer’s effort, it simply shifts it from the data warehouse/data lakehouse (where it belongs) to the semantic layer. The semantic layer is not well suited to implementing transformations. It also shifts the processing workload from batch/overnight data warehouse loads, where the data is transformed and prepared by the data warehouse/data lakehouse for the semantic layer, to query time, when the end user has to wait for the transformation to occur while they run their report.
The semantic layer becomes the sole purveyor of the semantic model. The modern data warehouse is designed to support various usage scenarios besides ad-hoc analysis, reports and BI. Today, the modern data warehouse must support Data Science workloads, non-real-time data integration (i.e. reverse ETL), near-real-time analytics, etc. These workloads often require fine-grained and/or high-volume data rather than aggregated data. Semantic layer software excels at aggregated queries but not fine-grained high-volume row-based ones. If you have a Data Warehouse/Data Lakehouse, use it to serve these fine-grained, high-volume, row-based queries. Then, use your semantic layer for what it is best for – serving aggregated analytical queries. Horses for courses!
The History and Future of Semantic Layers
Prepare for a rant!
Unfortunately, the concept of a semantic layer got lost in the vendor-driven, VC-backed “data warehouse is dead”, data analyst-centric collective nightmare of the modern data stack that valued agility over all else! In the melee, we lost the consistency of meaning, reuse and sustainable data assets that data warehouses were designed to deliver.
The problem with data warehouses was never the concept; it was the execution. Back in the ’90s and ’00s, business users were very frustrated by how long it took to create what seemed like a fairly simple report. Couple that with the explosion of data that stressed the state-of-the-art databases at the time, and it’s true that something had to change.
Personally, I believe we should have (and could have – with automation) addressed the methodology of delivering data warehouses. Unfortunately, the data warehouse baby got thrown out with the bath water. Instead, we got “Big Data” (Remember Hadoop, etc.) and Self-Service BI. The “Big Data” hype cycle was driven by the very largest organisations (the Facebooks and Googles of the world) and pumped by the consultancy industry onto organisations that didn’t have the same big data issues. Consultancies love this kind of disruption. It puts bums on seats and $ in the bank. “Big Data” was a monumental flop, but out of the ashes emerged HDFS and Spark. Spark is the open-source distributed computing technology underpinning Databricks, Microsoft Fabric and other analytics platforms. Self-service BI was a myth that gave organisations the excuse to favour agility over sustainability. The result was “data swamps” and a reemergence of the “single version of the truth” problem and other issues that data warehouses were designed to fix.
However, now, finally, things are changing. We are seeing the signs of the industry awakening from its coma. The emergence of the Data Lakehouse architecture acknowledges that the Data Warehouse concept is still valid. The Modern data warehouse, I think, is still overly complicated, but now, rather than being purely reporting/dashboard/analysis focussed, we have a unified platform that can serve more usage scenarios like Data science/analysis, real-time analytics and ETL, operational system analytics APIs, embedded BI and reverse ETL.
Even better news: the industry is recovering from its amnesia around semantic layers. In the 90s and 00s, semantic layers were regularly implemented with software like Microsoft Analysis Services, Business Objects Universe, etc. Unfortunately, semantic layers didn’t fit the narrative and were discounted and “forgotten”. Thankfully, the semantic layer is making a renaissance, as it should, as businesses encounter the reemergence of the problems that data warehouses were designed to solve.
There is new (and existing) software that is focused on implementing a Semantic layer. The emerging software sometimes uses new terms (e.g. Headless BI, Metrics Layer) as synonyms for a symantic layer. Headless BI may be slightly different as it implies that the semantic layer is not delivered within or alongside a visualisation platform.
The software can be divided into roughly 3 groups:
- Stand-alone tools like Cube, AtScale, Denodo, Kyligence.
- Embedded within a Visualization platform. E.g. GoodData, PowerBI, LookML.
- Meta or Virtual layers like the dbt offering. In dbt Core/Cloud, it’s possible to define metrics over your models using a metrics language. Dbt is developing a dbt Server in dbt Cloud that allows a visualisation client to connect in real-time, get metadata about available metrics, and then query the dbt server. The dbt server interprets the query using the metric definitions, generates an SQL query, executes against the underlying database, and returns the result. Other similar tools work in a similar way but have other strengths. Examples are Malloy, Metriql, MetricFlow, and Lightdash.
Semantic later software has needed to evolve from the narrow BI focus of the 90s and 00’s to serve a more diverse set of usage scenarios of the modern data warehouse. A semantic layer must now be accessible for more usage scenarios like Data science/analytics, operational embedded BI, reverse ETL, etc.
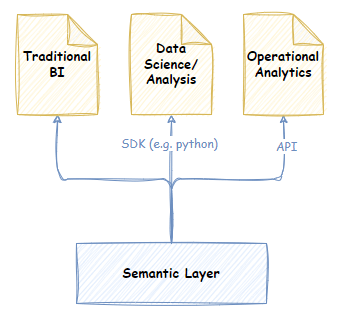
Thankfully, nearly all of the above tools have responded to this need. Many provide APIs, SDKs for Python, JDBC/ODBC interfaces, Robust metrics language, etc. Semantic layers are now able to play a wider role in promoting a common business language for end users and data professionals across any usage scenario.
The future for semantic layers is looking bright!