
Incremental Extract Pattern
The incremental extract pattern allows you to extract only changed data from your source tables/views/queries, reducing load on your source systems and overall ETL duration. I.e. To do change data capture (CDC) at the source.
The pattern generates code that extracts only changed data from your source databases. For example, you could use this pattern to extract only transactions from a large transaction table that have been inserted or updated since the last time the extract was executed. For the pattern to work you need to identify a column or multiple columns that the source system uses to track change. These columns are called ‘Change Data Identifier’ columns. They would usually be a modified date or sequential identifier.
Each time the Extract is executed Dimodelo saves the maximum value that was extracted for the ‘Change Data Identifier’ column(s) to the Control Parameters table in the Staging database. Subsequent executions of the Extract only retrieve data from the source where the ‘Change Data Identifier’ column(s) value in the source is greater than the maximum value stored by the previous invocation of the Extract. This is the mechanism Dimodelo uses to manage your incremental extracts.
How to use this pattern
For a Staging table, in the ETL dialog, select the ‘Incremental Extract’ pattern for the Extract. See below (click to enlarge ).

It is possible to define the source of the extract as either a table/view or query. To define the incremental extract for a table/view, first select the table/view in the ‘Table or View’ drop down. See below (click to enlarge).

Then in ‘Change Data Identifier’ table, select the column(s) that are the ‘Change Data Identifier’ columns. You can select any column in the table/view. It’s also necessary to supply an ‘Initial Load Value’. The ‘Initial Load Value’ is used in the Extract the first time it runs. The idea is to set this to a very low value, so that the initial run of Extract does a ‘Full Extract’, selecting all rows in the source. You can tailor this to your needs. For example you may only want rows for the past 3 years.
If you have more complex Extract requirements, it may be necessary to write a query. In this case it is still possible to do an incremental Extract.See below (click to enlarge ).

In the query you must refer to your ‘Change Data Identifier’ columns as @ChangeDataIdentifierColumnName where @ChangeDataIdentifierColumnName is any name you choose. The query should be something like:
SELECT …
FROM …
WHERE ChangeDataIdentifierColumnName > @ChangeDataIdentifierColumnName
However you can write much more sophisticated queries if necessary. Then in ‘Change Data Identifier’ table, select the column(s) that are defined as @ChangeDataIdentifierColumnName in the query and supply an ‘Initial Load Value’ value. The ‘Initial Load Value’ is used in the Extract the first time it runs.
How the generated code works
As stated previously, each time the Extract is executed Dimodelo saves in the control Parameters table the maximum value that was extracted for each of the ‘Change Data Identifier’ column(s). When you define your source as a table/view, Dimodelo generates a query with the appropriate @ChangeDataIdentifierColumnName placeholders for each ‘Change Data Identifier’. The query would be something like
SELECT *
FROM Table
WHERE ChangeDataIdenitifierColumnName > @ChangeDataIdentifierColumnName
This query is used as the query for the source component of the SSIS package data flow. When you define your source as a query, DA sets the query in the source component of the SSIS package data flow to the provided query. Before the SSIS package data flow is executed, the package retrieves the maximum value of each ‘Change Data Identifier’ column(s) that was stored in the Control Parameters table by the previous invocation of the Extract. The maximum value is substituted for the @ChangeDataIdentifierColumnName in the source query prior to the data flow being executed. It is also possible to include DA’s standard batch control properties (like batch_effective_date, batch_execution_id) as parameters in the query. Just include them as @controlpropertyname. Read the Managing and Monitoring ETL batches Guide for more information about batch control properties.
The incremental extract pattern works for both ODBC sources (which can take a query) and OLE DB sources. It doesn’t work for excel and file sources, by their very nature usually represent a batch of records, or are small in size. If you need to do this with a file source, then connect to it as an ODBC source.
Reloading all records
With the incremental pattern it is possible to reload all records from the source (or a subset of all records) by changing the values stored in the Control Parameters table.
The image below shows the content of the ControlParameters table in the Staging database. You can edit the value for your initial value parameter. The next time DA executes the Extract, it will use the updated value from the ControlParameters table.
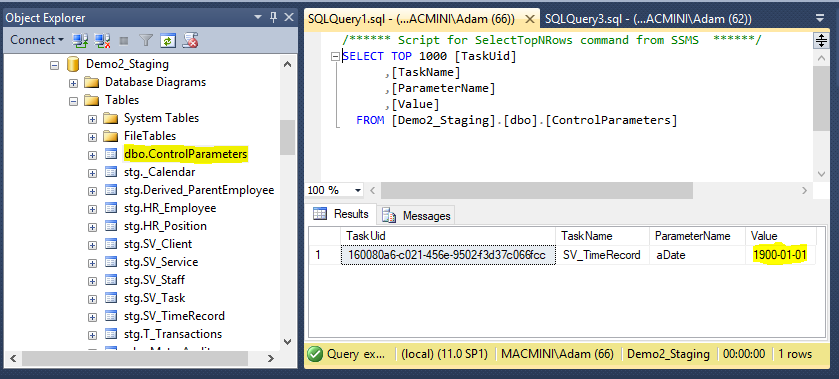
Note: Dimodelo puts an ‘a’ in front of the parameter name to eliminate clashes with reserved words when generating SQL statements.
Using the Incremental Pattern with RowVersion/Timestamp
- First, the Rowversion column in the Dimodelo staging table should be defined with a Binary(8) data type, or a varbinary(8) if the source column is null.
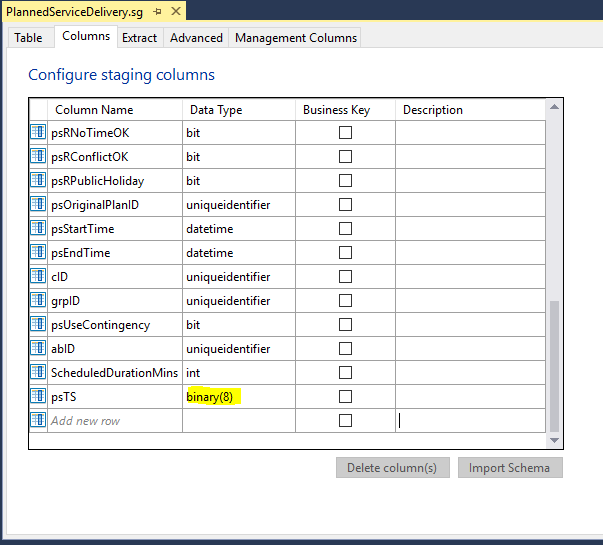
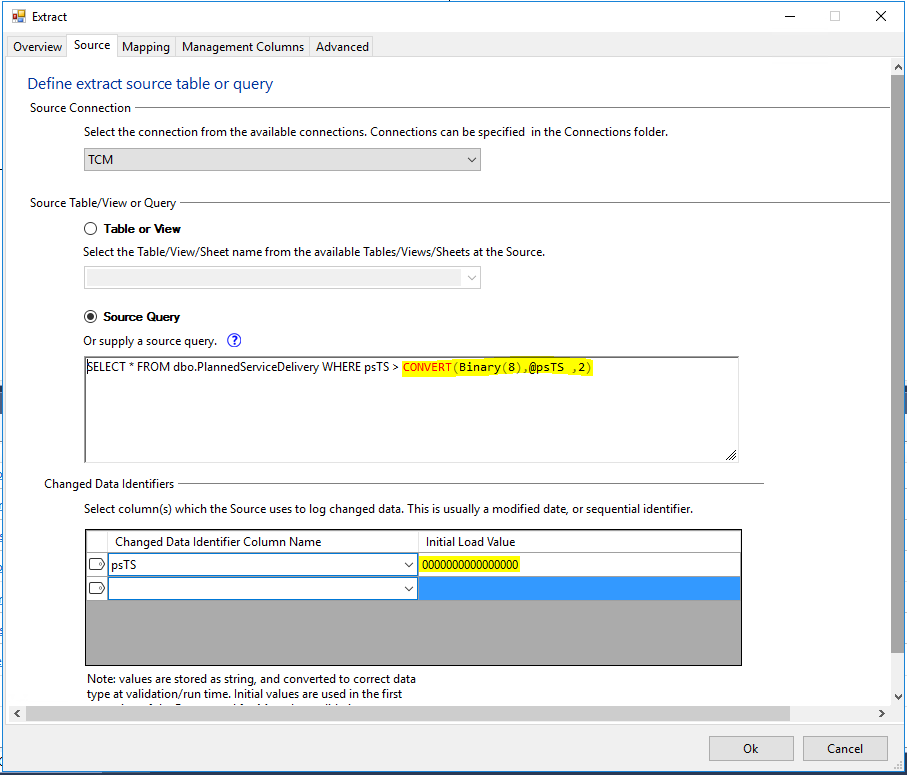
2. Define the Extract as an Incremental extract based on a query. The default code generated when you use a table as the source doesn’t work in this case. Use Convert with style 2 to convert the change identifier to a binary(8) value. Set the initial value for the change identifier to a 16 digit hexadecimal value without the leading 0x.
See below:
More about binary style conversions can be found here – https://docs.microsoft.com/en-us/sql/t-sql/functions/cast-and-convert-transact-sql?view=sql-server-2017